{kind=link}
{kind=link}
{kind=link}
{kind=link}
LIVE MEASURED
Observed on a running system with recorded measurement artifacts.
How we know ATOMiK works today
ATOMiK proof is organized by evidence tier. Performance claims must be quoted only with their artifact, workload context, and caveat. Do not isolate the biggest number without the interpretation.
Interactive · HARDWARE_VALIDATED
Pick your aggregation and the throughput-at-correctness bar you gate commitment on, and see the silicon-measured verdict live — 800 Mevents/s at 8 banks, byte-identical across 1/2/4/8 banks on the AX7020. We'll run your workload live on the board on request. Open the benchmark tool →
Public proof packet
The current proof stack is artifact-bound: a Zynq UI proof image, Linux userspace-to-FPGA validation, and a live-measured AX7020 workload matrix with wins, losses, and caveats. The next evidence gate is customer-representative Zynq workload validation.
Artifact map
The public site links to the evidence and benchmark page, hardware proof map, claims registry, and evidence labels.
Evidence labels
Claims are separated as live measured, hardware validated, software validated, formal proof, synthesis validated, build artifact, projected, conceptual, or roadmap.
Claim control
The registry records public-safe claims, artifacts, caveats, and overclaim risks for current public materials.
Hardware validated
ATOMiK Desk v0.40-A is the current UI captured live from /dev/fb0 on Zynq hardware, with on-screen metrics driven by real measured on-board data. It is not proof of power, thermal, uptime, or production maturity.
Live measured
An 8-bank XOR accumulator on the AX7020 scaled linearly with allocated banks (1/2/4/8x fewer cycles, about 100-800 Mdeltas/s at 100 MHz), measured with an on-chip cycle counter. The result was byte-identical across every bank count and matched a software recompute - order-independent and lock-free by construction. It is the throughput substrate, not a customer-workload speedup or power claim.
Live measured
The Workloads surface (real-time telemetry aggregation) runs on the AX7020 over HDMI driven by live measured throughput from the parallel-bank engine: 800 Mevents/s at 8 banks, with byte-identical results across configs. The first customer-facing workload demo proven end-to-end on hardware. Throughput is measured; it is a static capture, not an interactive session.
Live measured
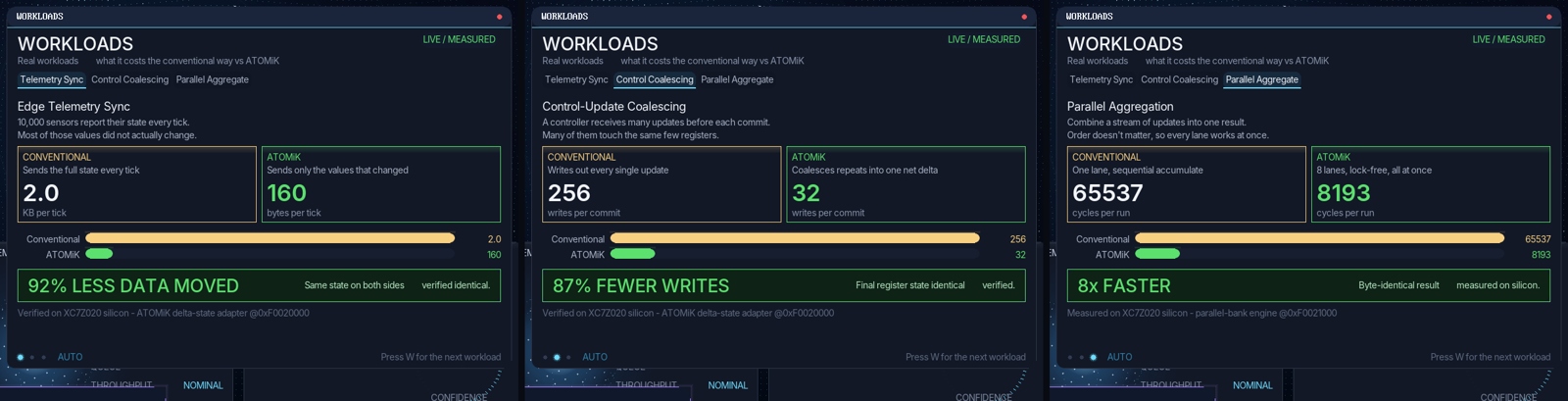
The redesigned Workloads surface shows conventional-vs-ATOMiK side by side on the AX7020: an edge-telemetry sync tick moves 2,048 bytes conventionally vs 160 bytes as deltas (92% less data moved), and 256 control updates coalesce into 32 net writes (87% fewer). Every delta was verified on the ATOMiK adapter with exact 64-bit round-trips using a falsification-tested harness, and the demo self-drives through all three scenarios untethered. Figures are for deterministic test patterns (ratios scale with change density and locality); static captures, not an interactive session.
Live measured
All three customer Workloads scenarios on the AX7020 with the production typography: telemetry sync (92% less data), control coalescing (87% fewer writes), and parallel aggregate (8x faster). The two memory scenarios are adapter-verified with exact 64-bit round-trips; parallel is measured on the bench engine. Ratios are pattern-dependent, not universal multipliers; static captures, not interactive.
Hardware validated
The Linux userspace proof validates the path from user process through Linux, MMIO, Wishbone CSR bus, and FPGA accelerator for algebraic checks.
Live measured
The matrix shows ATOMiK can win in specific coalesced/batched scenarios and lose in others. Use it with the interpretation caveats.
Formal proof
Formal proof work is present in the repository. Public pages should avoid unaudited proof counts unless the count is verified across repo, site, and deck.
Synthesis validated
Synthesis and toolchain outputs are useful evidence but must not be blended with live-board measurements.
Roadmap / conceptual
Concept visuals explain product direction only. They are not proof of current commercial functionality.
Downloadable technical packet
These are public-safe proof digest files and machine-readable exports. They support diligence without turning the public homepage into a raw artifact dump.
Download
Nontechnical digest: what each artifact proves, what it does not prove, and safe language.
Download
Prevents blending v0.40-A UI proof, AX7020 matrix proof, parallel-bank throughput, Linux validation, SD boot, and formal proof.
Download
Compact workload-specific readout of the live-measured AX7020 matrix.
Download
One-page summary of Linux userspace-to-FPGA validation and boundaries.
Download
Machine-readable CSV export for technical review.
Download
Machine-readable summary and caveat file.
Download
Required caption for the v0.40-A hardware UI artifact.
Download
SHA-256 hashes for downloadable public proof artifacts.
Evidence labels
LIVE MEASURED
Observed on a running system with recorded measurement artifacts.
HARDWARE VALIDATED
Demonstrated on physical hardware without implying production readiness.
SOFTWARE VALIDATED
Shown in software prototype, simulation, local runtime, or formal work.
SYNTHESIS VALIDATED
Supported by toolchain output, separate from live-board measurements.
FORMAL PROOF
Directly audited formal statements only; do not use as workload, customer, or production proof.
BUILD ARTIFACT
Concrete local build output exists, but the full path is not promoted as live proof.
PROJECTED
A model or estimate. It must not be phrased as an observed result.
CONCEPTUAL
Explains direction or UX. It is not current functionality.
ROADMAP
Planned work that may change.
What each proof does and does not prove
HARDWARE_VALIDATED
What it supports: The current ATOMiK Desk UI image was captured live from /dev/fb0 on Zynq hardware, with on-screen metrics driven by real measured on-board data.
What it does not support: It is not a customer workload benchmark and does not prove power, thermal, battery, uptime, footprint, or production maturity outcomes.
HARDWARE_VALIDATED
What it supports: A live framebuffer capture of ATOMiK Desk on Zynq hardware with apps open and the Resource Fabric showing on-board metric values driven by the real measured metric-provider layer.
What it does not support: It is a static capture, not an interactive session: it does not prove the in-flight interactive Workloads demo or USB keyboard/mouse input, and it is not a customer workload, power, thermal, or production-maturity claim.
LIVE_MEASURED
What it supports: The Workloads surface (real-time telemetry aggregation) runs on the AX7020 over HDMI showing live measured parallel-bank throughput: 800 Mevents/s at 8 banks, 1/2/4/8x throughput scaling, and a byte-identical result across all bank configurations. The first customer-facing workload demo proven end-to-end on hardware.
What it does not support: Only the throughput figures are measured; the Resource Fabric lane values and top-bar temperature/efficiency readouts are derived or scenario data, not measured proof. It is a static capture, not an interactive session, and does not prove the in-flight USB keyboard/mouse input.
LIVE_MEASURED
What it supports: The redesigned conventional-vs-ATOMiK Workloads surface on AX7020 HDMI: an edge-telemetry sync tick moves 2,048 B vs 160 B (92% less data moved) and control coalescing reduces 256 updates to 32 net writes (87% fewer), each verified on the ATOMiK adapter with exact 64-bit LOAD/ACCUM/READ round-trips and a falsification-tested harness. A paired capture mid auto-cycle (14-workloads-coalescing-selfdriving-ax7020.png) shows the untethered board advancing scenarios by itself.
What it does not support: Ratios are for deterministic test patterns (92% at 5% change density; 87% at this update locality) - not universal multipliers, power, thermal, or customer outcomes. Self-driving means auto-cycling, not interactive input; USB keyboard/mouse remain in flight. Fabric lane and top-bar values are derived/scenario.
LIVE_MEASURED
What it supports: An 8-bank XOR accumulator on the AX7020 scaled linearly with allocated banks (1/2/4/8x fewer cycles, about 100 to 800 Mdeltas/s at the 100 MHz sys clock), measured with an on-chip cycle counter, with a byte-identical result across every bank count that matched a software recompute. This is the literal embodiment of the order-independent, lock-free shared accumulator.
What it does not support: It is the measurement bench engine, not the production application adapter, and not a customer-workload speedup, power, or thermal claim. Quote figures at the 100 MHz sys clock.
HARDWARE_VALIDATED
What it supports: The ATOMiK Desk UI renders at 1080p30 over HDMI on the AX7020.
What it does not support: 1080p60 is physically impossible on this board: the OSERDES2 minimum-pulse-width limit fails on the 737.5 MHz serializer. Claim 1080p30 only; 720p60 is the achievable true-60Hz path.
LIVE_MEASURED
What it supports: A recorded board run produced software, direct hardware, batched, and profiled results on the AX7020 path.
What it does not support: It does not prove ATOMiK is always faster. The interpretation shows wins in specific coalesced/batched scenarios and losses in others.
LIVE_MEASURED
What it supports: The honest readout: naive hardware access can lose, batching can help modestly, and coalescing can drive the meaningful win when the workload fits.
What it does not support: It does not validate SYNC bytes-avoided behavior in the current matrix because the document records that limitation.
HARDWARE_VALIDATED
What it supports: ATOMiK algebraic checks passed through a Linux userspace to kernel/MMIO/Wishbone/FPGA path.
What it does not support: It does not by itself prove production readiness, battery improvement, or thermal improvement.
SYNTHESIS_VALIDATED
What it supports: Toolchain and hardware/synthesis characterization exists for parallel accumulator configurations.
What it does not support: Synthesis ceilings must not be quoted as live-board performance unless a matching board-run artifact exists.
CLAIM CONTROL
What it supports: Public-safe claims, labels, artifacts, caveats, and notes are tracked in one registry.
What it does not support: The registry is a control surface, not a substitute for the linked raw artifacts.
FORMAL_PROOF
What it supports: Formal proof work is present in the repository and can be reviewed in technical diligence where a directly audited statement is identified.
What it does not support: Public pages should not repeat unaudited proof counts unless the count is verified across repo, site, and deck.
Performance warning
The current interpretation says ATOMiK can win when batching and coalescing match the workload, and can lose when naive hardware access or high unique-region ratios dominate. The honest claim is workload-specific: ATOMiK is strongest where state movement, repeated scans, full-state sync, replay, or reconstruction dominate the cost.
- Do not say ATOMiK is always faster.
- Do not claim proven heat, battery, water, or footprint improvements without artifact-backed measurement.
- Do not treat concept visuals or synthesis ceilings as live performance proof.
Bring one workload, one baseline, and one constraint. ATOMiK will map the evidence tier required before making any public or diligence claim.
Request Evaluation{kind=link}